Message Batching
It is worth outlining the batching mechanisms and what is trying to be achieved with them.
Constraints
It is assumed the following constraints are desirable:
- Clients are delivered messages in a fair manner with as little latency as possible
- No Client should dominate the send time to the detriment of other clients
- Clients should see the same shared message at as close to the same time as possible (a client should not see a message too far ahead of another if they share the same message topic)
- For a single Client no topic should starve or delay messages from other topics
- The normal mechanism of use is many clients with many topics.
How Clients are processed
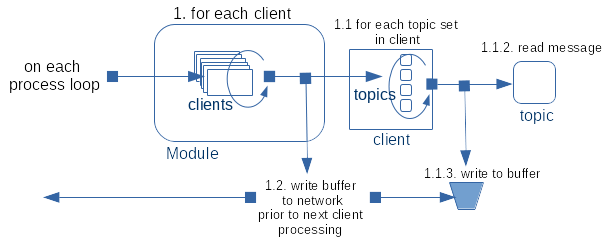
The above diagram is rough approximation as to how Clients are processed on each processing cycle.
However, there are some complexities with this that need expanding:
- We do not want to iterate over all clients just the ones that are ready to take data.
- The client is not always in a fit state to have data sent to it (no long poll waiting, blocked on a write etc)
- We do not want to check all clients as only those with pending data and in a fit state are processed
- Within a client not all topics have data waiting to be sent.
- We do not want to check every handle as each iteration would be linear to the total handles not just active handles
The main problem is that in order to have reasonable performance we must cut down from potentially checking n topics x n clients to only processing active handles for clients which are in a state where they can send data and which have a pending message.
The obvious mechanism that deals best with this in the OS is an epoll type idiom. Therefore the best approach would be a select of clients in a ready state and a select of only those topics that have data pending. This gives us m users x m topics to deal with.
To achieve this we have an approach that:
The pending clients are stored in a bespoke data structure in each module. This is defined as:
- for Long polling * Clients that have issued a long-poll HTTP GET leads to the the client marked as active.
- For Websockets * Client sockets are always potentially active (unless write blocked) so the indication is any onMessage or RPC response marks the client as active.
The clients in this structure are processed on each processing select loop. Repeated topic writes for the same client result in a single callback entry in the pending list:
module -> [ClientA, ClientB ...]
Similarly for each client there is a data structure of the Handles which have called back to indicate pending data. This is driven by the onMessage() call in most cases from the application code. Repeated calls are coalesced into a single notification for that handle id.
Client -> [ handleA, HandleB, HandleC]
Repeated calls for HandleA does NOT result in the structure below (this would produce a huge internal queue that would rapidly lead to latency and memory issues for repeated updates):
Client -> [HandleA, HandleB,HandleA, HandleA]
The Client additionally has a single Direct queue which stores all RPC responses and other priority messages as a single queue.
Therefore from the calling code perspective every onMessage(Object ob) call is an event which will result in:
- Within the Client handle set: * no effect (if the message is on a topic and that handle has already notified a callback) * addition of a topic handle to the client’s topic set if a new handle * addition of a message to the direct queue if an RPC response
- For the client Set * no addition to the pending Clients (if already notified for any other message) * a new entry in the pending Clients set.
We also want the onMessage call to do as little work as possible in the application threads.
Default batching approach
With this structure in mind the default batching strategy is this:
- Process each client at a cost of (m)/(n) with (m) being active clients out of a total client set of (n) connected.
* For each Client
- Process all outstanding RPC or direct messages in the single client direct queue (they are assumed to be important for StateOfTheWorld type messages) until the queue is empty or the buffer is full (cost is (n) for number of messages in queue)
- If any space remains for each active topic:
- read a message from the topic handle and write to the client buffer. This cost is (m)/(n) with (m) being active handles as a proportion of (n) topics the client is subscribed to.
- If the handle has pending messages after this retain that handle and notify ourselves that the topic requires processing in the next poll cycle.
- when the outbound buffer is full
- If any handles from the current set have not been processed add them into the pending set for the next cycle and notify ourselves
- return and write the buffer to the network.
- Or all the handles have been processed and we can return to write the buffer to the network
- read a message from the topic handle and write to the client buffer. This cost is (m)/(n) with (m) being active handles as a proportion of (n) topics the client is subscribed to.
This strategy provides for linear processing of the active clients, and within each client minimal processing of the active topics and direct messages. It provides batching for each client to the extent that the topic handles are treated equally to reduce starvation of later topics by earlier busy topics and data is taken fairly from each topic.
Topics that are fast moving and report as yet unconsumed messages are bumped for the next cycle and are processed in front of other later arriving handles. So fast moving handles in some respect push themselves to the front of each cycle and do not get left behind or backed up behind later arriving topic handles.
Assuming that the time between the poll cycles is not huge this means each topic gets a fair chance to push its data to all users around the same time and within a client the topics have a relatively equal standing.
Similarly we can see that the clients are treated fairly to the extent that the topic numbers being equal, each client’s cost is approximately equal and no single client can dominate the entire poll cycle.
Additionally where data is shared by more than one client we can see that this approach also tries to ensure that Message1 is delivered to both ClientA and ClientB in the same push cycle as far as other factors allow. This is very important for pricing and similar where you want the data to be quick and fair so ClientA does not see the data (as far as is feasible) at a vastly different time than ClientB.
Batching and Queues
There are essentially 2 different forms of Handle and this impacts the batching in some respects:
-
Private Handles * Only a single User session has access to this handle * Data is queued by default and overflow on this handle (for slow moving clients) results in back pressure for the caller.
-
Shared (group or otherwise) Handles * Multiple users or multiple sessions for the same user can connect * queueing is either: - None - Last message is returned as a snapshot to be sent to new arrivals without waiting for a tick - Queued - a ringbuffer of data - with each client retaining a pointer index into the buffer as to where it is up to. There is no backpressure overlow and the data simply wraps (the clients are able to signal data loss when they are processing the messages in handle)
Non-lossy shared Queues
Why Do Shared or Grouped Handles not have non-lossy Queues?
This seems a reasonable question at first glance but if we think about what a shared handle represents we will see that it is basically one of physical behaviour that makes it an immensely complex problem to manage in a practical manner.
If all clients on the channel are able to process data instantaneously on each message tick and never lag there is no problem. This easily overlooked - but this is not how the real world works.
We can see from the above active client description that even under normal ideal conditions, Clients polling readiness and network roundtrips are variable, let alone having to deal with asymmetric topic subscription volumes, blocked clients, TCP packet loss throttling and browser stalls.
The Real Problem
The real statement is therefore given a requirement to not lose messages how do we deal with clients processing a non-lossy queue of messages without wrapping/loss when they process at different rates?
-
We could use the pointer approach per client to keep track of where they were in the single queue and reject new messages on the handle if any client was behind far enough to lose a message. However, this means that: * All clients would be as slow as the slowest Client on the handle * a stuck or blocked client would prevent any messages at all being sent to any user * If we kicked off the slowest clients if they were behind - how far is behind? * Each client would have to be compared as to where it was up to relative the head on each message push (making this order (n) of all clients on each handle for each onMessage call) * thresholds would need to be set on clients that were behind. This would have to be able to deal with spikey lagging versus real lagging (how are we to decide this?), recoverable timing thresholds and hard cut offs * Slow clients would need to be disconnected to maintain a thoughput for other clients (this would mean either callbacks on the client’s own activity or each onMessage having to be returned a set of slow users). This would be VERY expensive.
-
We could keep an internal queue for each Client on the handle. * this means that message overhead would move from per handle to per client/per handle. So 1000 clients on 1000 topics would result in 1 million queues just in the handles. Each onMessage push would be order (n) queue commits with number of clients. * Even if we took this approach the message would need writing into each queue individually on each push in an atomic manner. if some queues failed what would we do? * Reject the message - effectively the topic is now stuck and no more data could be sent * Disconnect the user (again this leads to the same problems as above) * what level of queue would be acceptable ? - memory sizes would be huge and processing costs could be VERY large.
We can see that if we think about it, non-lossy shared queues are a practical problem that produces huge knock on complexity and fragility in operation.
In many ways its analogous the CAP problem for distributed databases. Synchronously sharing data without loss to multiple consumers on an apparent single topic across the network is not realistic.
We then take these issues above and realise that the situation is not bounded to a single topic, but is a force on each topic handle for the each client, across multiple clients. This is a substantial multiplier.
As a side note this approach is entirely analogous to delta messaging support in shared queues and has the same drawbacks (which is why delta messaging is explicitly excluded as a behaviour.
What does that have to do with batching ?
If we step back a little we realise that the lack of shared non-lossy queues impacts the applicability of batching with a single shared handle to the extent that the batch ceases to have a strong definite meaning given over-writes in the both the snapshot and ring-buffer queue form of the Shared or Grouped Handle.
So let us examine this a little further and assume that if a batch is a more loosely defined concept we can still achieve some greedy consumption from shared data handles even if we can tolerate data loss in the batch.
Automatic Greedy Batching
Why can we not greedily consume up to the network buffer size from the handles per client?
i.e given
topic 1: [a b c] (queue)
topic 2: [d e f] (queue)
topic 3: [g] (snapshot)
can we not have a single cycle that is:
message: [a d g b e c f]
For a Single Client
Initially let us not examine the issues this creates with regard to asymmetric Client domination and giving Clients on the same topic large temporal variance in the delivery of the same message. Let us instead examine what this means for a single client.
The problem seems simple conceptually with the above diagram, but in reality the diagram is:
topic 1: [...] (queue)
topic 2: [...] (queue)
topic 3: [...] (snapshot)
There is an unknown set of data on each handle as far as the process is concerned at time point t.
So we have to iterate over the handles to find out what our state is and initially produce
message [a d g]
so far this is our (m) cost.
We then iterate over the handles again
message [a d g b e ]
This is now 2(m)
When we get to topic 3 what do we do? We cannot get rid of the message in the handle as we need to retain it to send to other clients potentially acting on this handle concurrently or arriving on other modules at the time this is being processed.
Therefore we would need to know we have already processed Message(g) from topic 3. This means either being able to look back into the messages (at least log(n)) we have just written or for each handle keeping a list of the message (by hash or some form of monotonic counter sequence) the message we have seen from 3.
Additionally we have a further choice if the handle is effectively not supplying a message for iteration 2. Do we discard it from the set ?. But what if another message arrives in the meantime as we iterate over the other handles. Do we not want to add this message as part of the same batch (remember all the messages are concurrently pushed to the handles while this happening)?
So lets assume we can do this and take the cost of the message check and extra book-keeping. Now we iterate again.
message [a d g b e c f]
Let us now assume topic 3 has been updated -so we add another message
message [a d g b e c f h]
this is now 3(m) - its still 3(m) even without the extra topic3 message.
If we have more space in the buffer we cannot know that the handles are empty without checking each one, or recording if they still have pending data as we go along per iteration.
So we need to iterate over all the handles again to make sure they are all empty (this is now 4(m)).
The best case now moves from m/n topics * m/n clients to x(m)/n topics * m/n clients, with x being potentially large.
With even a low number of 100 topics per user this becomes very large and would lead to significant delays in delivery for the later clients in the cycles.
Further, if even one handle has a message remaining in each iteration we would need to keep repeating this until all were null - giving us a large x(m) overhead. While not unbounded this is problematic. This is assuming the data on the handles is static and is not being updated while this cycle continues (which it is not).
Alternatively we could remove the handles that had nothing pending at time point (t) and not look at them again in this iteration. But again we would end up effecitively iterating until all handles were quiescent or the buffer was full. 1 handle could keep us iterating for a long enough time (relatively speaking). Given the set is really an array - we would end up iterating over a sparser and sparser array until it was empty. Or have to keep a parallel data structure of the still active handles which we would need to keep in sync and produce an iterator for.
However, we also need to consider our full client population here. During this time other clients would lose the ability to consume messages from this handle - as an arrival rate on the topic paced to a single consume rate would forward through the ringbuffer for just this client - leaving other clients to suffer from a higher rate of data loss or struggling to catch up. As by the time they got their turn the ring buffer would have advanced some proportion (let us say c) defined by the batch size of each client * the number of previous clients in that process cycle.
e.g each Client consuming 10 messages (assuming a similar arrival rate as the consume) would fill the ring buffer (assuming a default of 64) before we got to client 8. Client 8 would have lost access to all 70 previous updates.
For all Clients
Further let us now examine this in relation to the client population in the cycle.
For each client in each cycle there is a concept of time to first byte in a cycle and time to message(p) of a topic.
If we have 1 or 2 clients then consuming as much as possible for each client is intuitive. However that is not really the problem we are trying to solve. In reality we have many clients and the view of the messages across all clients must be seen as the relative time of a message instance is seen by not just client1 but also client(n), relative to client1.
The time for the default approach is proportional to the client set (n) * (handles (h) + buffer write(w)).
So for a single handle, client1 sees message1 at time t and client(n) sees first byte and message1 at a time proportional to n. In fact all clients in each cycle have a constant time gap between each message of approximately n. So message2 is delivered to client1 at a gap of n relative to its receipt of message1 and so on.
If we adopt a greedy approach what we see is that this changes to n * ((m * h) + w). So let us say that in the simple case there is only 1 topic with some messages.
client1:[topic1:m1,m2,m3,m4,m5 ...]
client2:[topic1:m1,m2,m3,m4,m5 ...]
client3:[topic1:m1,m2,m3,m4,m5 ...]
client4:[topic1:m1,m2,m3,m4,m5 ...]
clientn:[topic1:m1,m2,m3,m4,m5 ...]
We can see that now client(n) would not see m1 relative to client1 until n * m. With the gap between each clients first byte and message(p) no longer proportional to the client number only, but varying depending on the cumulative queue depth of each client in sequence. It is easy to see that the latency becomes tail oriented and clients suffer this relative gap to a greater extent the more clients we add and the greedier each client is.
For shared multiple topics this visibility skew in the clients relative to each other becomes more pronounced as in reality we would like the clients to view the same data item at as close to the same time as possible (within reason). Assuming batching of all pending messages in the handles:
client1: [topic1:m1,m2,m3][topic2:m1,m2,m3][topic3:m1,m2,m3]
client2: [topic1:m1,m2,m3][topic2:m1,m2,m3][topic3:m1,m2,m3]
client3: [topic1:m1,m2,m3][topic2:m1,m2,m3][topic3:m1,m2,m3]
client4: [topic1:m1,m2,m3][topic2:m1,m2,m3][topic3:m1,m2,m3]
...
clientn: [topic1:m1,m2,m3][topic2:m1,m2,m3][topic3:m1,m2,m3]
We can see above client(n)’s view of the message1 in topic1 relative to client1’s will suffer a further and further skew the more messages we consume from each topic even though we actually want the message visibility to be approximately equal (given it represents the same data item).
It is also worth noting that message buffer write is not free - so the larger the buffer the longer it takes to write each buffer adding onto the subsequent latency to some degree.
The batching across topics also has this effect to some degree, however in that case we still see message(n) of each topic at a time still relative to the client number. So the clients have effectively a more stable constant time factor for each time slice across the topics:
client1: [topic1:m1][topic2:m1][topic3:m1]
client2: [topic1:m1][topic2:m1][topic3:m1]
client3: [topic1:m1][topic2:m1][topic3:m1]
...
clientn: [topic1:m1][topic2:m1][topic3:m1]
...
client1: [topic1:m2][topic2:m2][topic3:m2]
client2: [topic1:m2][topic2:m2][topic3:m2]
client3: [topic1:m2][topic2:m2][topic3:m2]
...
clientn: [topic1:m2][topic2:m2][topic3:m2]
Here we favour latency reduction for all clients’ view of the messages relative to each other and try and minimize the gap between first byte for each poll cycle.
Dominator clients
Similar to topic starvation we alluded to earlier we can also see that a very busy clientA would effectively disproportionately consume processing to the relative starvation of the other clients in the cycle. We could make a case that we are optimising for message throughput in this case (for a specific client).
However, the smaller clients will see larger gaps than between their small number of messages than we would expect given the addition of a few more busy clients. This effect becomes pronounced proportionally the more busy clients we add. (E.g think of a queue at a bank counter where the person in front changes 10000 pound coins, and then joins the back of the queue and does this again. Other customers become dominated by this time).
In many ways this is similar to the pre-emptive time slicing that modern OS’s use. Each active process that registers an OS interrupt is generally given a time slice quanta (t) to perform its actions. If it gives it up earlier then great the next process runs sooner.
However, the OS tries to ensure that a few busy processes do not completely starve other processes and as more processes are added they are allocated the same quanta. All OSes adopt this approach (unless they are specialized) as experience shows us that it the best trade-off for competing resources for competing asymmetric demands.
Real Problem
In reality this problem is one of being able to know the future.
The code has to be able to know the current state of all the handles it is about to process for a client, predict the future arrival rate on the set of topics, and be aware of demands of the as yet un-processed (and unknown) pending handles for the total set of clients in the set it is processing in this loop in order to make this practicable. In addition in order to prevent temporal skew of clients across cycles we would have to book-keep clients and reorder their processing to try and amortise this behaviour.
Looking at it from the perspective for a couple of clients it seems tricky but perhaps manageable. However, if we broaden our view to the real operation where we are not dealing with single clients; and even with a low number of a few hundred of clients with many topics we can see that this knowing the future problem becomes too much of an issue.
As Karl popper points out in the “Poverty of Historicism” in order to predict the future you have to know the future, making it no longer the future but information we have in the past.
Unfortunately, we do not have all the information available at the beginning of each cycle in order to correctly choose a variable future behaviour for the best outcome under all circumstances - so we must make a trade off.
In practice (unless we have very few users/connections) time slicing has shown to be the least problematic approach in preserving relative performance across multiple users. Indeed irrespective of the approach we take the OS will time slice the read,write and application threads for us without significant action to prevent this.
Batching for Private Handles
With all that said there is some ability using the Batch annotation or specifying the Batch Provider interface for Private topics to achieve something similar to above for an individual client. This enables a pattern of more data across few topics to be performant.
The effect of this is that within an iteration, a topic (if private and batch enabled) will be polled until its batch number is satisfied, or it is empty, or the send buffer is full.
Taking the example above this would give a result of:
topic 1: [a b c] (private queue) (batch 5)
topic 2: [d e f] (private queue) (batch 5)
topic 3: [g] (snapshot)
message: [a b c d e f g]
This approach can achieve an effect close to the effect specified above, in effect each topic supplies a mini-batch within the overall batch, however this has some of the drawbacks and one should keep in mind the following caveats:
The batch number should not really be set at a level that the size of the individual messages * the number is larger than the outbound buffer size. If it is substantially larger then the batch size that actually results will be smaller under normal conditions, but under conditions of an initial very large message causing an outbound buffer resize, it is easy to get into the situation where a lot of data is batched produced which causes a slow down in the push out onto the sockets.
Similarly, batching has the capacity to starve other handles in the read cycle if the topic is very busy.
For instance if the batch size is 10 and this fills the outbound buffer on each cycle (if messages are produced quickly and continuously) then any pending messages on other handles are deferred. Depending on order arrival cross the handles this can happen repeatedly greatly increasing the latency of messages in other topics.
Batching within a topic like this is not a panacea and it is Strongly preferable to split messages into multiple topics rather than have 1 or 2 topics and try and rely on batching to overcome the single topic anti-pattern.
It is therefore only really useful to use batching if you are forced into using a very small number of topics due to data structure and still want to optimise throughput if you have bursty messages being produced. Alternatively it could be useful where a topic has occasional bursts and you want to effectively prioritise these as a single block over the general consumption as part of the other handle consumption.
The addition of this intra-topic batching is therefore opt-in for each Private Channel so the application code can decide to accept these behaviours as it is more aware of its expected data profile.
The batching is applied to all handles in a particular Channel. This then enables a different batch depth to be applied to different topics (if they are in different channels), giving some ability weight the messages from one channel over another.
Conclusion
By default we then have each batch being a greedy consumption of direct messages + a parallel slice through all the topics pending for a client. All topics are candidates, so topics across different channels are treated as a flat set.
For Private topics we can (with some caution) add a batch within a topic for some set (n) of messages as a mini-batch block within the overall batch as shown above.
For each Client, each push is a push of a batch of this structure. And each push cycle is for a batch of clients.
The entire batching should act to encourage multiple topics to be used for users, with some scope for batching bursty private topics.
A case could be made for some further intra-topic batching for Shared Topics which had a ring-buffer queue configured - but this is probably not as useful in practice as in initial concept of the happy path with single or small numbers of clients (as outlined above).