Large Messages from the Server
When working with Rubris it is important to realise that it is intended to be a messaging platform and large messages can have an adverse behaviour on performance.
It is worthwhile explaining what we mean by “large” by referring to the diagram for batching.
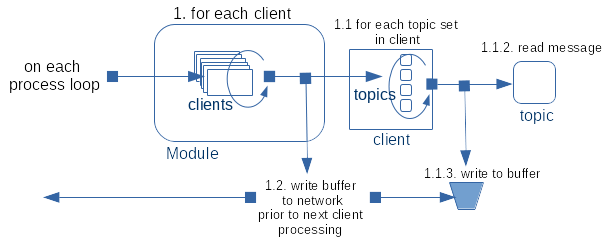
The important part to focus on here is that at stage 1.1.3 the message is written to the outbound buffer. A large message for Rubris is one that is unable to fit in the current buffer when it is the first message to be written. This is handled differently than multiple messages that just fill the buffer and remaining messages do not fit because of this.
The definition of “large” is a property of the config for that instance and is configured as per the setting for the WriterPool.blockSize. This is used to allocate a pool of buffers that Rubris uses for each outbound write per client. Normally this will be in the 128k/256k range.
Rubris takes the approach that if the message is too large to fit in this buffer only when it is the first message to be written, a buffer from the large pool is retrieved and the message is written to that.
If other messages have already been written to the buffer prior to this then the message is deferred to the next cycle (irrespective of size) and the buffer so far is flushed to the network leaving the message as the first candidate for the next write cycle. We can see from this that multiple smaller messages do not cause a buffer resize and the algorithm is greedy in consumption upto the current buffer size at which point it writes out the existing data. This cycle is repeated until the condition of the previous paragraph is encountered and the fist message is oversized.
This is entirely to prevent large messages tieing up other smaller messages and becoming dominators in scheduling.
The Large pool size is defined by the Write Pool definition in the configuration. If the message is too big for the large buffer then Rubris will attempt to allocate new memory at increments of 2x largeBufferSize until either the message fits or we reach the maxUnpooledSize. If it is still too big the write will error and the connection will be closed.
It may be tempting to set these buffer sizes to very large values and hope for the best. However, we have to deal with the real world and the following factors should be taken into account:
-
The larger the default buffer the longer each batch of messages will take to write/process and transmit. * e.g a default of 512k might seem a good idea but you will be penalising each subsequent client and make each HTTP response to the client consist of many more TCP packets. This approach skews behaviour to delivery to a single client over a fair spread to all clients (assuming equal message updates).
-
The larger the default the less buffers will be available in the pool and the less theoretical clients you will be able to support (if you need to retain the buffers across cycles in case of blocked writes etc).
-
The larger the buffer the more likely you will get blocked write scenarios in the OS defined by EWOULDBLOCK responses causing delays in sending a response as the writing thread has to now manage data that could not be sent atomically on the socket and must be retained for subsequent cycles.
This last point is often ignored but is very important so it is worth going into detail about it.
Memory considerations
Memory for Large messages is handled in by the the Write Pool definition for the Module.
The pool has a default size (default 256k) and a large size scale factor (usually 4). Blocks of the 256k size are pre-allocated as part of a memory mapped file and a similar file to support a smaller number of large blocks at 4x the default size (the large file is capped to 500Mb so increasing the scale will reduce the number of blocks available).
This means that in nearly all cases even messages upto 1mb will use the preallocated memory pool and no other memory will be allocated.
However, blocks larger than this up to the max block size (default 16 x size) are allocated as new Direct Buffers (in this case the max is therefore 4Mb). This leads to a much longer path for allocation and also may lead to memory issues or even core dumps on the machine if the memory is very quickly allocated and not released correctly.
If you find more than the VERY occasional direct allocation in your log files then it is important that you resize your default correctly otherwise the application will be susceptible to stability issues.
Note: symptoms include inability to allocate stack memory, excessive garbage collection, native OOM or even core dumps.
Blocked Writes
When Rubris attempts to write a buffer to the socket the total bytes it can write is bounded by the TX buffer size for that Socket in the OS.
An attempted write that does not write all the bytes in the buffer to the socket in one go (what would be a blocked write) means that Rubris has to somehow stash the remaining data and wait for the TX buffer to be flushed to the network before anything else can be sent on the socket.
This is achieved by registering the socket in a selector for a write event (which signifies the buffer is now empty). At this point the write selector thread will schedule the client as enabled again and the remaining bytes will attempt to be flushed before processing any other messages.
This can of course mean that slow clients can cause lots of wasted processing time, blocked writes and extra work by trying to continually write to buffers that are slow to flush.
Accordingly, Rubris adopts a penalising mechanism where repeated blocked clients are progressively deferred scheduled processing time (using a formula of (failedSends/blockedWriterScaler) x slot duration). The defaults mean that the client is paused for the time of slot duration x number of blocked writes and this is incremented on every nth blocked write. These values are set in the WriterConfig
So 2 blocked writes in the same cycle will be paused for ~n ms per write (+ potentially some fraction of the current blocked write period) + the OS time to clear the buffer + register of select + overlap with normal process schedule.
The failedCount is reset if the gap between fails is longer than failedSendResetTime in the writer config.
So what does this mean for Large messages?
If we have a large messages of say 1mb and a default buffer size of 256k, not only will we get repeated buffer writes to larger and larger buffers as Rubris attempts to scale the outbound buffer (which takes time) but we are almost certainly sure to get blocked at least once writing to the OS (and likely to be more than one). The effect of this is that for very large messages you will see largish increases in time of delivery for that message depending on the buffer/OS settings.
The effect of the slow down can be changed by shortening the slot duration and/or the sale factor but if you find yourself doing this it may be useful to step back and examine what design decisions are forcing this to occur.
Although the OS TCP buffer size can be altered to amortise this using the SocketConfig sendBuf property size (and indeed should be set according to the shape of your data) it is very unlikely that the client RX TCP stack will be scaled in the same way.
Significantly extending the OS size is really only shifting the issue to the OS and the network which will increase the memory per socket, increase the latency of the data between the server and the client and increase the number of packets per message (and accordingly chance of packet loss).
As in all things there is no single answer that can deal with all scenarios. There are only trade-offs and simply having large messages with with large buffers and large OS TX sizes is pushing the bolus of this large atomic data to the network, which will push itself back into the application quite quickly. Sympathy to the network and architecture should encourage one to think even from the outset about sizings resulting from even simple things like choice of transport data format (e.g JSON is very verbose).
Compression for Server messages
In order to mitigate some of these above effects it is possible to enable compression at the message level for some (or all) of the endpoints.
Compression is automatically added to messages above a certain size on an endpoint by using the following interface as a mixin on the endpoint. This means a message batch can be composed of some,all or no compressed messages intermingled with uncompressed messages.
public interface MessageCompression { public int compressAt(); }
The default the algorithm used is deflate at level 1.
This is because:
- it is by far the quickest and resource light compression level for a good trade off (especially for data such as JSON. Higher levels of compression trade off a few % of space for a much longer running time.
- there are good JS libraries to decompress deflate data and level 1 reduces the CPU time on the client.
The compression code will attempt to compress any messages that are greater than the configured length. During compression if a 50% space saving cannot be achieved the compressed data is discarded and the message is sent as is.
The compression is done at a per message level, rather than transport, so during batches the payload on the client may well contain a mix of these.
The use of the compression requires the client library to be correctly configured. See the Client Guide for details.
Generally the compression is meant for those cases where the messages for whatever reason are not really able to be decomposed and works best if you are passing text like formats that are heavily redundant.
However, It is possible to set the compression directly to override the default one by using:
public interface MessageCompressor { public byte[] compress(byte[] data); }
Of course one could also pre-compress the data prior to writing and mark the payload as such using the payload of the message if required.
The fact a message is compressed is indicated to the client by ORing the message type with a high bit indicating compression. The resulting message type is therefore something similar to RPC|COMPRESSED.
The compressed flag is only valid for RPC/PUSH and CONVERSATION messages.
The client masks off the high bit on receipt of the message and then determines the type. Earlier client versions will see these messages as an invalid type.
Compression for Client Subscribe Messages
Similar to the above situation, it is also possible to configure the client to compress its subscribes. See compressed subscribes.
If you use the pako approach as detailed in the docs (or similar deflate library) then there should be nothing to do. However, you may have customised the compression algorithm and therefore you may want to override the default algorithm. Note: size can be tweaked using the config only.
The mechanism to achieve this is to supply in the handlers list an object implementing the MessageDecompressor interface. Note: the interface is not implemented on any other handler, it is simply a stanalone object. If multiple handlers are supplied, the last one will be used.
You must ensure this object is threadsafe as it will be called from multiple threads concurrently. However, it is not advised to implement locking or synchronisation to achieve this as it will affect the server behaviour. The recommended approach is entirely stateless (without allocation) or threadlocal patterns if the library requires internal state.
package com.rubris.api; /** * Interface that defines message decompression. * * The implementor MUST return the uncompressed length if successful or a 0/negative number if failed. * * @author steve * */ public interface MessageDecompressor { /** * @param inbytes the bytes containing the compressed data (offset is always 0) * @param length - the length of the compressed byte in the array * @param outBytes - the array for the uncompressed data. * @return Either a positive number if successful indicating the uncompressed length, or 0/negative if a failure. */ public int decompress(byte[] inbytes, int length, byte[] outBytes); }